CASE STUDY
From Instability to Scalability: Building an Event-Driven, Kubernetes-Based AI Platform
SWEDISH AI STARTUP, 2023
Context & Client Challenges
The client, a Swedish AI startup, offers Internet of Things (IoT) solutions designed to optimize commercial building energy consumption. Their daily operations rely on a cycle of data collection, processing, and machine learning: data is collected via API, an optimization process runs for each building every 10 minutes, and a daily training process updates building-specific models.
The initial infrastructure, hosted on Microsoft Azure, utilized Azure App Services for APIs and a self-managed Ray cluster for AI workloads. A SQL database served as a basic logging database but lacked support for critical metrics, alerts, or automated remedial actions. Code integration occurred via Bitbucket, while AI code deployment was entirely manual.
This architecture presented several significant operational and cost challenges:
-
Database Overload: Using a SQL database for high-volume logs resulted in excessive data volume and extremely slow query times. This lack of proper observability made fault discovery and timely intervention difficult, often leading to extended downtimes.
System Instability: The self-managed Ray cluster frequently froze, causing a backlog of optimization requests. The existing monitoring (an API-based dashboard showing buildings not optimized for over 30 minutes) lacked proactive alerting, meaning downtimes often went unnoticed for hours. The AI team sought a migration to a more stable execution environment.
-
Manual Deployment Bottlenecks: The manual deployment of AI code to the Ray cluster required stopping and restarting the entire cluster, causing operational downtime and hindering development velocity.
Inconsistent Build Environments: A fast development pace combined with a pre-baked testing image on Bitbucket often caused errors when new packages were introduced. The AI team required a system that dynamically built container images before testing and deployment to production, ensuring consistency between development and production environments.
-
Rapid development led to a proliferation of unoptimised and often inappropriately sized Azure resources. The company faced continuously increasing infrastructure bills and needed immediate asset hygiene measures to control these escalating costs.
The Solution
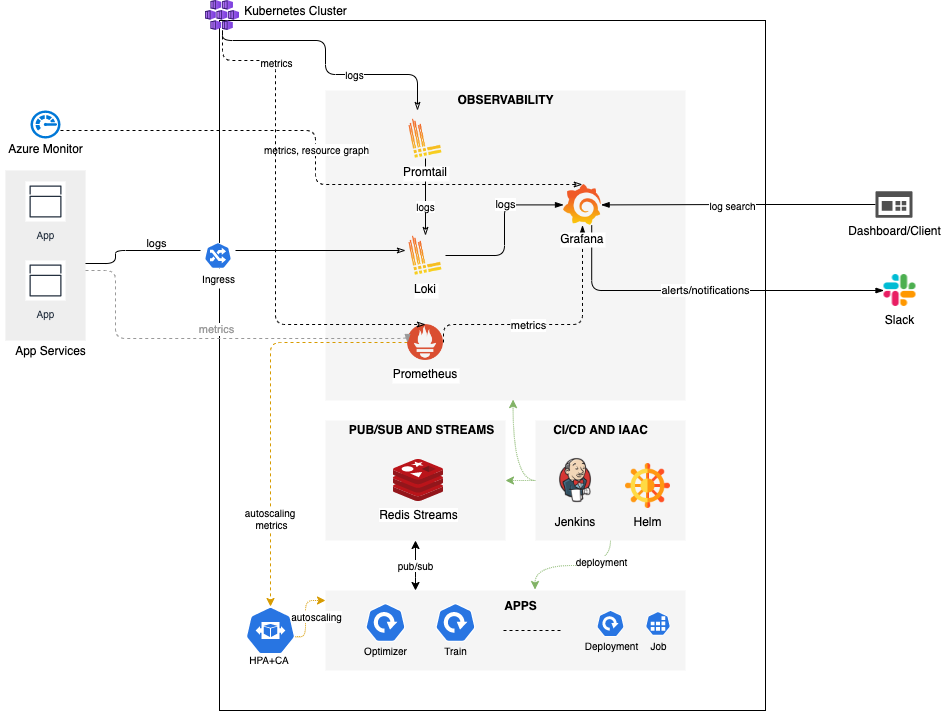
The solution was a comprehensive re-architecture of the client's platform into a new Kubernetes-based platform designed for AI at scale, focusing on high availability, scalability, fault tolerance, disaster recovery, and operational efficiency. The core objective of the re-architecture was to replace the unstable, manual, and unobservable legacy system with a robust, event-driven infrastructure built on Azure Kubernetes Service (AKS)
Key Architectural Components
The new platform leverages several modern cloud-native tools to achieve operational excellence:
Kubernetes Cluster: The foundational layer running self-hosted applications, leveraging Azure constructs like Availability Zones (AZs) for resilience.
Observability Stack: A dedicated system for monitoring and logging.
Prometheus and Grafana for metrics and visual dashboards.
Loki and Promtail for log aggregation and search.
Azure Monitor integrates resource graphs and logs.
Alerting via Slack and Webhook applications enables proactive notifications and automated remediations.
Pub/Sub and Streams: Redis Streams were implemented for asynchronous communication between services, ensuring processes are event-driven.
CI/CD and IaAC: The build and deployment pipeline utilizes Jenkins and Helm for automated, reproducible deployments (Infrastructure as a Code).
Results and Business Impact
The implementation of the new, event-driven, Kubernetes-based AI platform delivered substantial improvements across all key operational areas. By adopting a modern cloud-native architecture, we successfully addressed the client’s performance, cost, and operational challenges, providing a foundation for scalable and reliable growth.
Enhanced Performance, Reliability, and Observability
The migration from a fragile, self-managed Ray cluster to a stable Azure Kubernetes Service (AKS) environment drastically improved system stability and incident response times.
-
The frequency of critical system outages was reduced by 99%. The previous issue of the Ray cluster "freezing" entirely was eliminated.
-
The new Prometheus, Grafana, and Loki observability stack enabled proactive monitoring and alerting via Slack. This reduced the average time to detect an issue from several hours (often overnight) to an average of < 10 minutes.
-
By migrating high-volume logs from the SQL database to Loki, log search and analysis times decreased from minutes to a near-instantaneous 2 seconds, enabling rapid debugging.
-
The Redis Streams-based event-driven architecture successfully processed high volumes of data asynchronously, completely eliminating the previous backlog of optimization requests.
Streamlined Development Lifecycle and Operational Efficiency
Automating the build and deployment process via Jenkins and Helm transformed the client's development velocity and reliability.
-
The shift from manual deployment to an automated CI/CD pipeline increased deployment frequency. Moving from a fortnightly deployment to daily deployment, allowing the AI team to iterate faster.
-
The time required to deploy new AI code was reduced from a manual, operationally disruptive 3 hr (which required a full cluster restart) to an automated process completed in under 10 minutes.
-
The automated, dynamic image build process solved the "inconsistent packages" issue, leading to a 95% reduction in deployment-related errors caused by environmental drift.
-
The client achieved an overall monthly infrastructure cost saving of approximately 35% within the first three months post-migration.
-
Leveraging the Horizontal Pod Autoscaler (HPA) and Cluster Autoscaler ensured resources were right-sized for actual demand, eliminating previous waste from over-provisioned VMs.
-
Optimizing container images by removing unnecessary dependencies reduced average image sizes from 16GB to 8 GB. This improved pod startup times by 50%, further enhancing performance and efficiency.
Significant Infrastructure Cost Optimization
The implementation of asset hygiene measures and leveraging Kubernetes’ inherent scaling capabilities immediately addressed the escalating infrastructure bills.